
上海微系统所在视觉人体姿态估计研究方面取得进展
近日,中国科学院上海微系统与信息技术研究所仿生视觉系统实验室李嘉茂研究员团队在视觉人体姿态估计领域取得了重要进展。团队围绕2D及3D人体姿态估计这两个紧密关联的任务,分别提出了创新方法,两项成果被计算机视觉与模式识别中国科学院一区期刊IEEE Transactions on Circuits and Systems for Video Technology (TCSVT, IF=11.1) 和IEEE Transactions on Multimedia(TMM, IF=9.7)录用,论文题目分别为“Hierarchical Contrastive Consistency for Human Pose Estimation in Images and Videos”与“MMCPose: Multimodal Condition-Driven 3D Human Pose Estimation via Diffusion Models”。
HICCON: 基于层次化对比一致性约束的2D人体姿态估计方法
2D人体姿态估计是一项面向人体对象的基础视觉感知任务,旨在通过图像或视频精准定位人体姿态关键点位置,为理解人体运动和行为提供结构化数据。然而,现有方法在复杂场景下难以兼顾空间定位准确性与时间运动连贯性,尤其在视频中如何保持姿态估计的稳定性是一大挑战。
为此,团队提出了一个高效的层次化对比一致性约束(HICCON),能够灵活嵌入多种姿态估计模型中,提升2D姿态估计性能。该方法在空间域上建模关键点与身体部件之间的关系,在时间域上捕捉帧与片段之间的运动模式。HICCON分别从空间与时间两个维度提取多层次特征——包括关键点级、部件关系级、实例级和片段级等不同粒度,并施加对比学习约束,增强模型对复杂姿态的判别能力。实验表明,在主流视频姿态数据集PoseTrack上,结合HICCON的多个模型均显著超过基准性能。本方法也表明了对比学习机制在人体视觉表征建模中的应用潜力和重要作用。
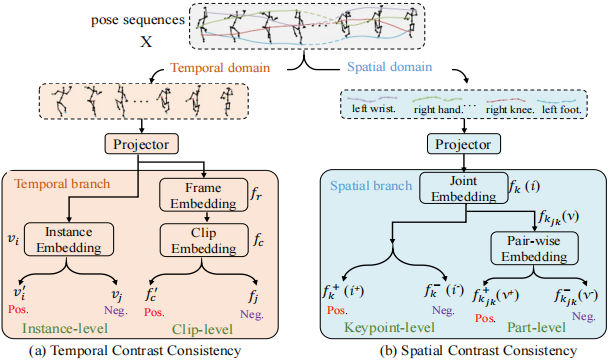
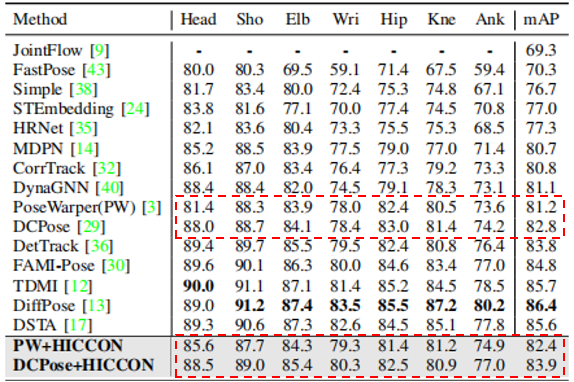
HICCON在PoseTrack数据集上相较于基准方法实现显著提升
MMCPose:多模态条件驱动扩散生成的3D人体姿态估计方法
在获得2D人体关键点基础上,3D人体姿态估计致力于恢复人体关键点在三维空间中的位置,这一技术在虚拟现实、运动分析、人机交互等领域有着广泛应用。然而,这一过程面临“深度模糊”等固有挑战,即同一组2D关键点可能对应多个合理的3D姿态。当前基于扩散生成式框架的方法虽然一定程度上缓解了这一问题,但由于模型缺乏对人体外观轮廓、语义理解等方面的认识,导致在预测中仍会生成不合理的姿态,这一问题在遮挡严重或人群密集等复杂场景下尤为突出。
为解决上述问题,团队提出了MMCPose模型,创新地将多模态人体先验作为条件信号,引导扩散过程生成合理且准确的3D姿态。模型融合了三类结构化信息:人体关节拓扑关系、基于自然语言的部件描述、以及提升姿态关注度的人体掩码。为了更好地发挥多模态条件的引导作用,还设计了一个多模态表征-姿态交互机制,实现引导信号与生成过程之间的深度交互,从而提升模型在姿态建模上的感知能力与生成质量。在Human3.6M和MPI-INF-3DHP等基准集上的测试表明,MMCPose取得了领先性能,特别是在Human3.6M上将平均误差降至30.8毫米。本方法也说明了多模态引导以及人体先验知识对于解决三维人体视觉感知任务的关键作用。
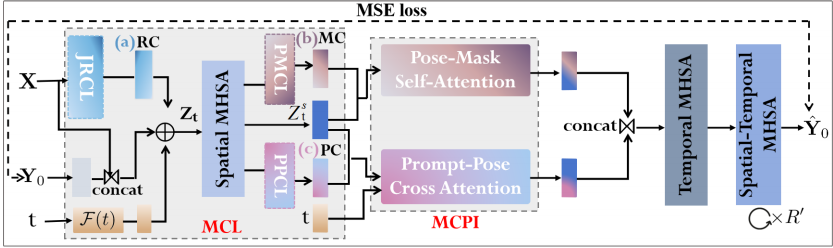
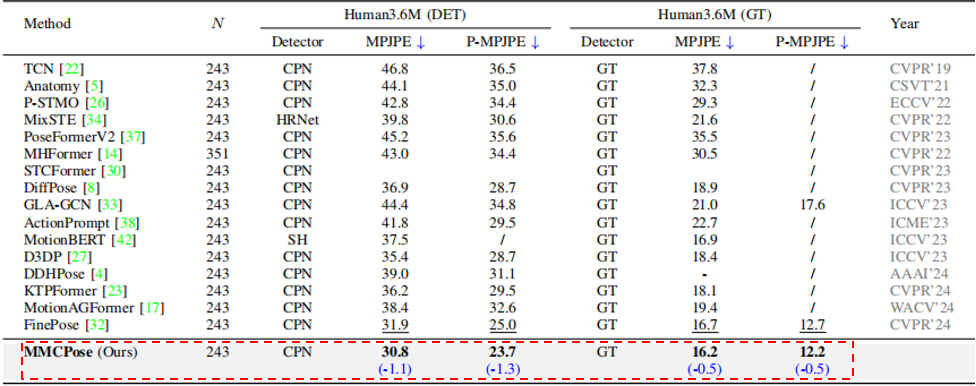
在Human3.6M数据集上MMCPose达到了最优性能
上述两项研究成果均得到了科技创新2030重大项目、上海市自然科学基金、上海市优秀学术带头人项目支持,上海微系统所仿生视觉系统实验室博士后徐稀侠为论文第一作者,实验室主任李嘉茂研究员为通讯作者。

